实训日记 | Day 03. 函数、包和数据库
总述
2020年7月22日。今天主要讲的内容有:
- 条件与循环
- 函数的定义
- 包的引用
- 连接MySQL
- 连接MongoDB
条件与循环
注意,以下语句都用到了此前提到过的代码块概念,若您已经忘记了,可以查看之前的章节复习。
条件if
使用类似如下的结构,即可在Python中创建一个条件分歧语句。可以把
1 | if condition_1: |
例如,要编写一段程序,判断输入的数字是否为1。
1 | num = input() |
循环for
for循环在其他编程语言中一般用来写已知循环次数的循环。Python也同样可以这样子做。
1 | for i in range(1,10): |
循环while
1 | astring = "Hello, Python." |
输出的内容是Hello。
在Python中没有类似do……while的语句。
如果想创建一个无限循环,可以使用while True:的条件。
循环else
在上面的for和while循环中,都可以再额外加入一个else:语句。
类似下面的例子:
1 | astring = "Hello, Python." |
else:语句的作用便是,在条件不满足时跳转到该代码块。
循环break
break可以用于终止整个循环。例如在下面的例子中:
1 | for i in range(1,10): |
不过需要注意的是,break仅会终止一个循环,对于嵌套的循环,它只会终止最接近的循环。
循环continue
continue可以用于终止当前这次循环,之后会马上进入下一次循环,例如在下面的例子中:
1 | for i in range(1,10): |
上述代码的结果是,除了5以外的1~9的数字。因为当i的值为5时,剩余的循环体代码被直接跳过了。
函数的定义
函数是一个有入口,有出口的程序段。它的作用有:
- 减少代码冗余
- 代码结构清晰
- 保持代码一致性
定义函数
定义函数使用def关键字即可。和大多数编程语言不同的是,Python在定义函数时不需要指定函数是否具有返回值/返回值类型/参数类型。
1 | def functionname(param1,param2,param3): |
上例中的pass关键字,是一个占位符。即你定义了某个函数,但是你还没有想好这个函数的具体内容时,用一个pass来占位以防止程序出错。
对于pass关键字,前面介绍的条件与循环中也是可以使用的。
例如:
1 | if a == b: |
接下来我们定义函数:输入两个数字,输出这两个数字的平均数。
1 | def zorua_average(a,b): |
上例的return关键字,就是用于指示函数的返回值。在函数返回以后,函数就结束了。例如下面的例子。
栗子
1 | def zorua_average(a,b): |
调用上面这个函数时,只会输出1,而不会输出2。
当然返回值并不是函数必须的。
由于Python在定义函数时做了极简,如果想像其他语言一样严格限定参数的类型,则需要进行参数变量的检查。这样也算是做到了类似函数重载的效果。
1 | def typeof(variate): |
默认参数
在定义函数时,可以给参数一些缺省值,这样在调用函数,没有给该参数的值时,参数会有一个默认的值。
1 | def functionname(param1=1,param2=2,param3=3): |
调用函数functionname()的结果为输出了1 2 3,等价于functionname(1,2,3);
functionname(4,5)的结果为输出了4 5 3,等价于functionname(4,5,3)。
默认参数应该要在函数定义时靠右写,有缺省值的参数在没有缺省值参数的右边。否则会产生二义性。例如
def func(param1=1,param2,param3)
的函数定义,那么func(3,4)的3和4到底是赋值给参数1和2,还是2和3呢?
关键字参数
对于上例,读者会发现,缺省参数只能依次填充。
如果我想做到param1,param2使用缺省值,而param3用自定义值,该如何做呢?
Python提供的方案是:functionname(param3=5),结果为结果为输出了1 2 5,等价于functionname(1,2,5)。
利用关键字参数,还可以改变参数的顺序。例如functionname(param3=5,param2=5,param1=5)
可变参数
在编程时,我们可能会出现的需求。
例如,参数数量是变化的一些函数:cal_sum(求和函数)。
- cal_sum(1,2)→1+2=3
- cal_sum(1,2,3,1)→1+2+3+1=7
那么,这在Python中该如何实现呢?
只需在这一个接受“多个内容”的参数的参数名前,加一个*即可。
值是以元组的形式传入的
例如下面的例子:
1 | def cal_sum(*number): |
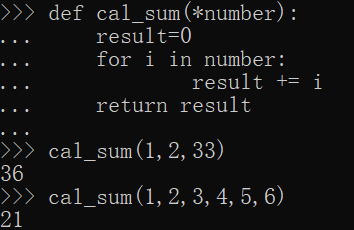
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。
至于到底传入了哪些,就需要在函数内部通过kw检查。
关键字参数的参数名前有**,值是以字典的形式传入的。
1 | def buy_item(id, number, **kw): |
但是这个时候,调用者仍可以传入不受限制的关键字参数。
例如
1 | buy_item(233,2333,discount=0.8,pay=12345,name="Zorua") |
另外还有一种形式的命名关键字参数,需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
1 | def buy_item(id, number, *, discount, pay): |
调用方式如下:
1 | buy_item(233,2333,discount=0.8,pay=12345) |
如果函数中有一个可变参数,上述的*可以用可变参数来代替。
即def buy_item(id, number, *args, discount, pay):
参数顺序
在默认参数这节中提到了默认参数应该在函数定义时靠右写,如果有更多类型的参数,则应按下面这个顺序从左到右:
基本参数、默认参数、可变参数、命名关键字参数和关键字参数
包的引入
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
1 | # 直接引入包 |
自定义包
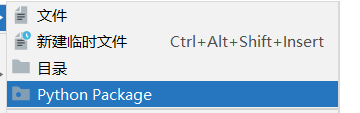
创建Python Package后,新建一个py文件,命名为__init__.py
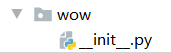
__init__.py 把文件夹变成包。
接下来就可以在其他代码中,使用import wow来引用这个包了。
导入顺序
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为
/usr/local/lib/python/。 - 模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
pip工具
pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。
一般在安装Python后,会自带这个工具。
在本篇文章中,只需要知道可以在命令行中使用pip install来进行包的安装即可。
后续如果有时间的话,我会额外写一篇文章来介绍pip3工具。
连接MySQL
援引自百度百科。
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
引入包
使用import pymysql语句引入包,如果还没有这个包,可以使用pip3 install pymysql进行安装。
连接数据库
1 | db = pymysql.connect(host='152.*.*.*',user='root',password='abc123456',database='Zorua0307',port=3309) |
注:*是须替换的部分,下同。
参数说明:
- host - 你的数据库地址,如果是本地的话,使用
192.168.0.*即可或者localhost。 - user - 用户名
- password - 密码
- database - 数据库名
- port - 数据库服务端口
创建游标
游标(Cursor)是处理数据的一种方法,为了查看或者处理结果集中的数据,游标提供了在结果集中一次一行或者多行前进或向后浏览数据的能力。
可以简单地把游标认为是记录的指针,以如下形式创建的话,默认为元组的形式(如图所示)。
1 | cursor = db.cursor() |

1 | cursor = db.cursor(pymysql.cursors.DictCursor) #默认是元组 换成字典 |

执行SQL语句
1 | cursor.execute('select * from students') |
使用cursor.execute()的方法可以执行类似上述的SQL语句。
获取数据
在执行完SQL的查询后,可以使用cursor.fetchone()将获取查询到的第一条数据。
cursor.fetchall()获取到查询到的所有数据。
更新数据库
执行关于更新(插入、修改等)的SQL语句后,需要提交才能完成对数据库的更新。可以参考下面这个代码。
1 | sql = "insert into student (name,age) values ('app',11)" |
关闭数据库
1 | #关闭游标 |
连接MongoDB
上一节简单介绍了,在Python中连接关系数据库MySQL。
这一节再简单介绍一下,连接非关系数据库MongoDB的过程。
关系数据库与非关系数据库
- 关系型数据库
- 一开始就定义好表的结构
- 非关系型数据库
- 可以随时增减字段 可以横向扩展
- 敏捷性和扩展性
- 学习成本低,降低企业费用
- 故障率低
- 跨平台
由于笔者对MongoDB也不甚熟悉,所以下面仅仅直接举出一些例子,暂时不作详解。
待日后学习,会及时跟进笔记。没错我又挖坑。
引入包
1 | from pymongo import MongoClient |
使用上述语句引入包,如果没有该包可以使用:pip3 install pymongo进行安装。
连接数据库
1 | conn = MongoClient('152.*.*.*',27019) |
如果是本地,可以使用localhost。
建立数据库
1 | db = conn['zorua'] |
使用上述语句,将创建一个名为zorua的数据库。
创建集合(表)
1 | my_set = db['zorua_set'] #集合相当于表 |
使用上述语句,将创建一个名为zorua_set的集合。
插入一条数据
1 | my_set.insert_one({'name': 'zorua', 'age': 19}) |
更新一个数据记录
1 | my_set.update_one({'name':'zorua'},{'$set':{'age':5}}) |
更新多个数据记录
1 | my_set.update_many({'name':'zorua'},{'$set':{'age':5}}) |
删除多个数据记录
1 | my_set.delete_many({'name':'zorua'}) |
查询记录
1 | result = my_set.find() |
 wechat
wechat alipay
alipay