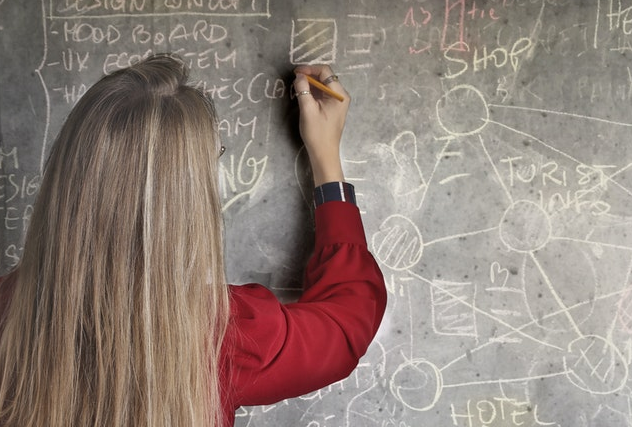实训日记 | Day 04. 简单的爬虫
总述
2020年7月22日。今天主要讲的内容有:
- 使用Requests包和BeautifulSoup4进行简单的网页爬虫
爬虫
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
我们知道,在WWW上我们访问的网页基本上都是用HTML文档来进行描述的。在浏览器按下F12键,可以打开开发者工具,选择Elements页签,即可查看HTML的文档内容。如图所示:
我们就可以从HTML中获取想要的数据/信息。
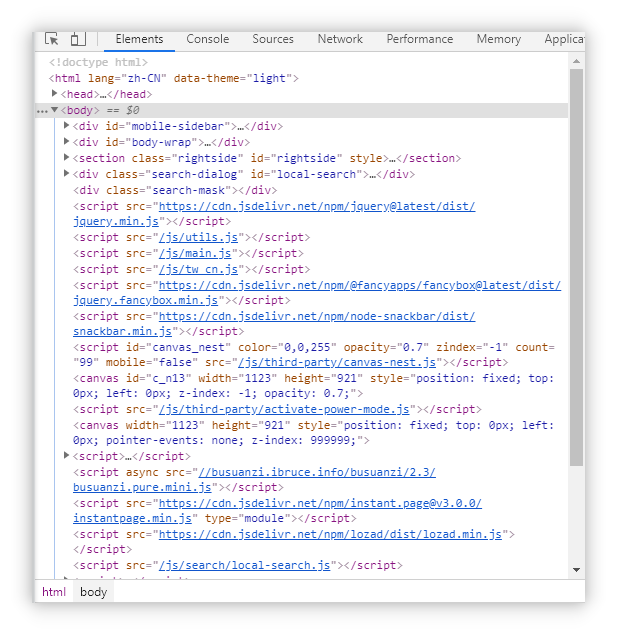
如果我们要进行对某个网页的爬虫,需要解决的问题有两个:
- 获取HTML文档的内容
- 解析这个HTML文档,按照一定规则获取其中的信息/数据
对于上面两个问题,进行针对性的解决:
- 用Requests包来获取HTML文档
- 用BeautifulSoup4来解析HTML文档
Requests

简单介绍
引用以下来自官方文档的内容:
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。
简单使用
如果你还没有安装Requests包,可以在命令行使用如下命令进行安装。
1 | pip install requests |
安装完毕后,键入如下代码:
1 | import requests |
这是以GET请求方式来访问https://www.baidu.com,然后返回一个HTTP状态码。
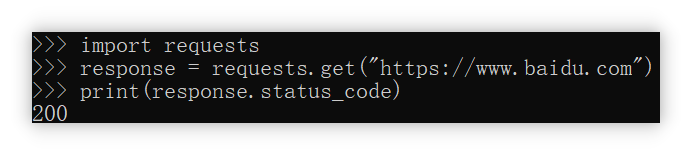
复习一下一些常见的HTTP状态码
200 请求成功
301/302 重定向
403 禁止访问 404 找不到资源 405 Method not allow
500 服务器问题 502 Bad Gateway 网关错误
上图返回的代码是200,即请求成功了。
请求成功后,可以获取一些其他信息。读者可以自行尝试输出查看内容。
这里主要说明response.text和response.content。
前者这个属性,获取了HTML文档,就解决了我们在前文提出的爬虫的第一个问题。
后者主要被用于存储图片和文件,例如访问的URL为https://zoruasama.gitee.io/img/zorua.png。
1 | print(response.text) #获取HTML文档 |
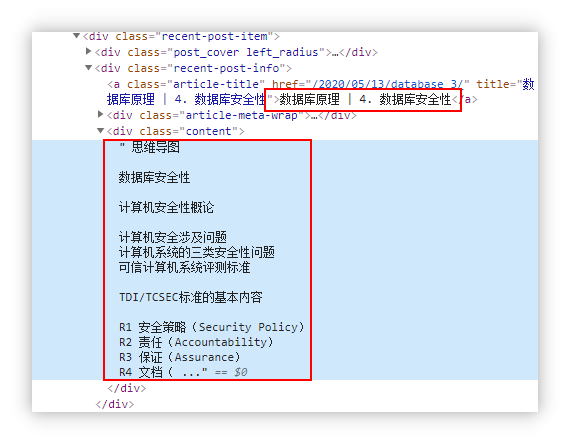
如图所示是response.text返回的字符串内容。

接下来说明如何使用BeautifulSoup4来获取HTML文档中的信息。
BeautifulSoup4
简单介绍
在线文档
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。
HTML 文档本身是结构化的文本,有一定的规则,通过它的结构可以简化信息提取。于是,就有了lxml、pyquery、BeautifulSoup等网页信息提取库。一般我们会用这些库来提取网页信息。
在下文中BeautifulSoup4将被简称为BS4。
简单使用
我们引用官方的例子来介绍如何使用BS4来进行工作。
先安装BS4,在命令行键入如下语句:
1 | pip install beautifulsoup4 |
假如我们已经使用某种方式获取到了某个网页的HTML文档(例如上文介绍的Requests),然后将这个文档字符串存储在html_doc这个变量中。
1 | html_doc = """ |
而后从bs4中引入BeautifulSoup,解析上面的文档,就能得到一个BeautifulSoup对象,并将之赋值给soup变量。
1 | from bs4 import BeautifulSoup |
使用对象的prettify()方法可以以标准缩进的形式呈现soup的HTML文档内容。
以下的内容需要一定的HTML基础。需要知道什么是标签,ID,Class等知识。
由于这不是本文主要内容,因此不再这里赘述,只会在下文简要说明。
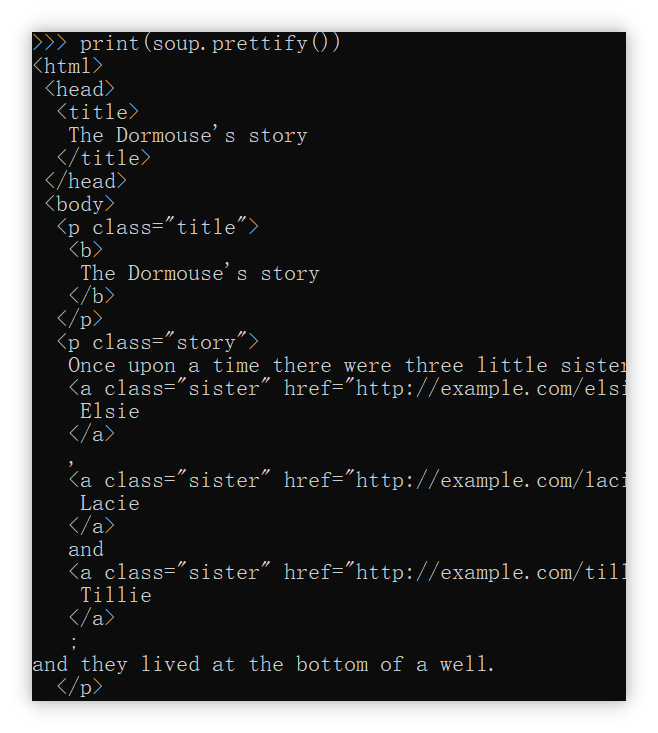
我们再来看看关于BeautifulSoup对象的其他方法:
1 | print(soup.title) #获取标题标签 |

接下来来解释一下上面这些名词。
soup.title
我们可以观察一下被解析的这个HTML文档,里面有一行:<title>The Dormouse's story</title>,两边用title标签裹着的。
因此soup.title就是在原先的整个文档中截取了这一部分。
同理,如果选择soup.body,那么就是输出body标签裹着的内容。

进一步再选择soup.body.p,这会输出body标签下的p标签,而p标签有多个,所以只会选择第一个并输出。
soup.title.text
虽然本节的标题是soup.title.text,但是text属性并不是title独有的,这一点在接下来的属性或方法介绍也是如此。只要是BeautifulSoup对象,都有这些方法。
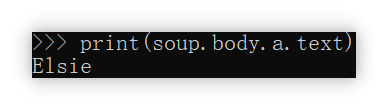
.text属性是用于获取标签内部的“正文”,如下图的橙色部分。
它没有在< >这对括号内,所以把它视为“正文”。

上面这段字符串,实际是通过soup.body.a来获取的。
接下来获取其中的“正文”。
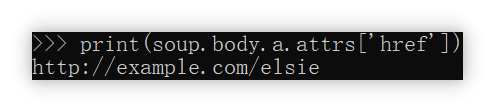
soup.title.attrs
在上文演示这个方法时,输出的是一个空字典。
这是因为soup.title并不具备属性。在本节我们拿上一节的soup.body.a作演示。

可以看到,在< >这对括号里的内容,以字典的形式被返回了。如果读者还没有遗忘如何从字典从取值的方法的话,很容易可以联想到:
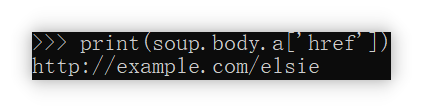
可以这样做,但是事实上,BS4还提供了一个优雅的做法:
soup.title.get(‘class’)
接续上节,获取< >内的内容,还可以使用本节标题的形式。
例如:soup.body.a.get('href')
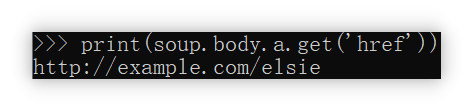
查找标签
大多数情况下,上述的简单使用总是只能获取到第一个匹配项,显得有些鸡肋、不够用。
而且对于标签的选择总是不够精准。
因此我们在这里介绍查找标签的方法。查找标签的方法主要有两个:.find()和.findall()。
前者也是查找第一个满足条件的标签并以字符串的形式返回,后者是查找所有满足条件的标签并以列表的形式返回。
除此以外,这两个方法在参数上大同小异。
name,标签的名字,例如p,a,title等。**kwargs,利用属性键值对来进行过滤。如id和class_等。- 其他的参数不再作解释。读者若感兴趣可以自行查阅文档。
查找指定id的标签
我们再次使用上面的HTML文档为例进行演示。

为了获取其中标为橙色的内容,我们可以soup.find('a',id="link2")。
查找指定class的标签

为了获取其中所有绿色的内容,我们可以soup.find_all('a',class_='sister')

返回的内容是一个含有三个元素的列表。
CSS选择器
如果您对CSS有了解的话,您肯定对 id 和 class 选择器不陌生。
使用soup.select()方法就可以像CSS的规则一样进行选择。
此处不再赘述。
例如
1 | print(soup.select('a')) |
实战演练
爬取百度贴吧帖子中的图片并下载
首先,我们先找一个百度贴吧帖子作为目标。
笔者选择了火影忍者吧的这一帖子作为目标 链接。
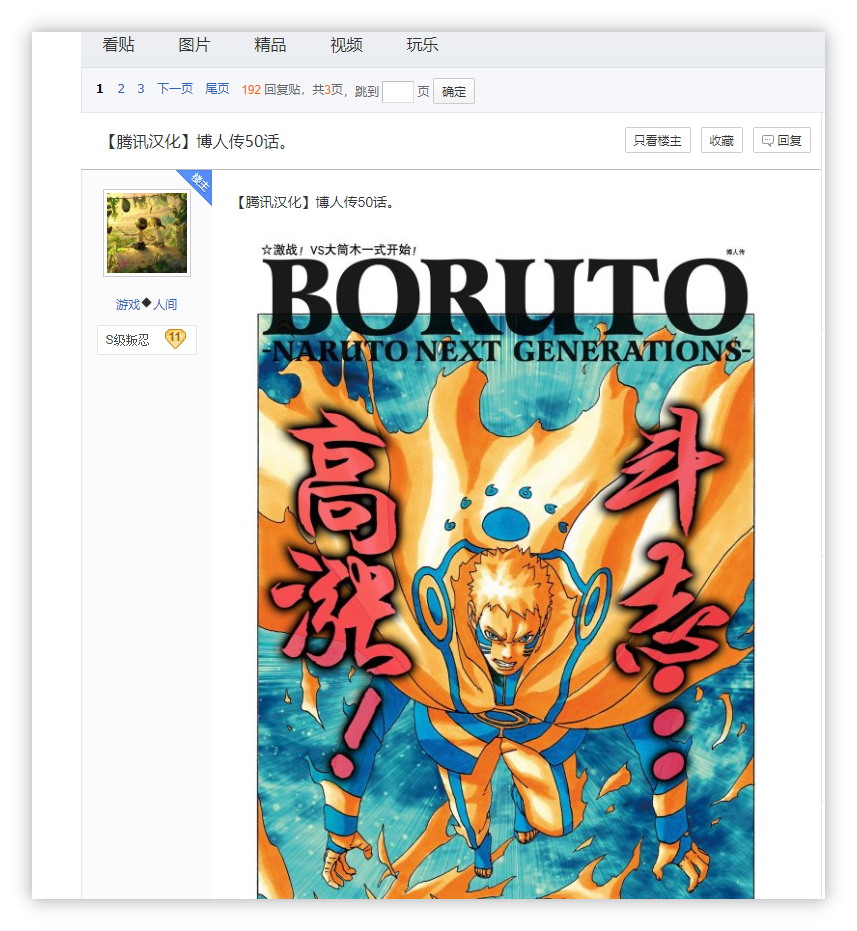
获取HTML文档
先使用requests获取文档。
1 | import requests |
用BeautifulSoup解析
1 | from bs4 import BeautifulSoup |
对网页元素进行选择
为了方便对HTML文档的阅读,我们使用浏览器的F12工具进行阅读。这个工具只需在浏览器中按下F12键即可打开。
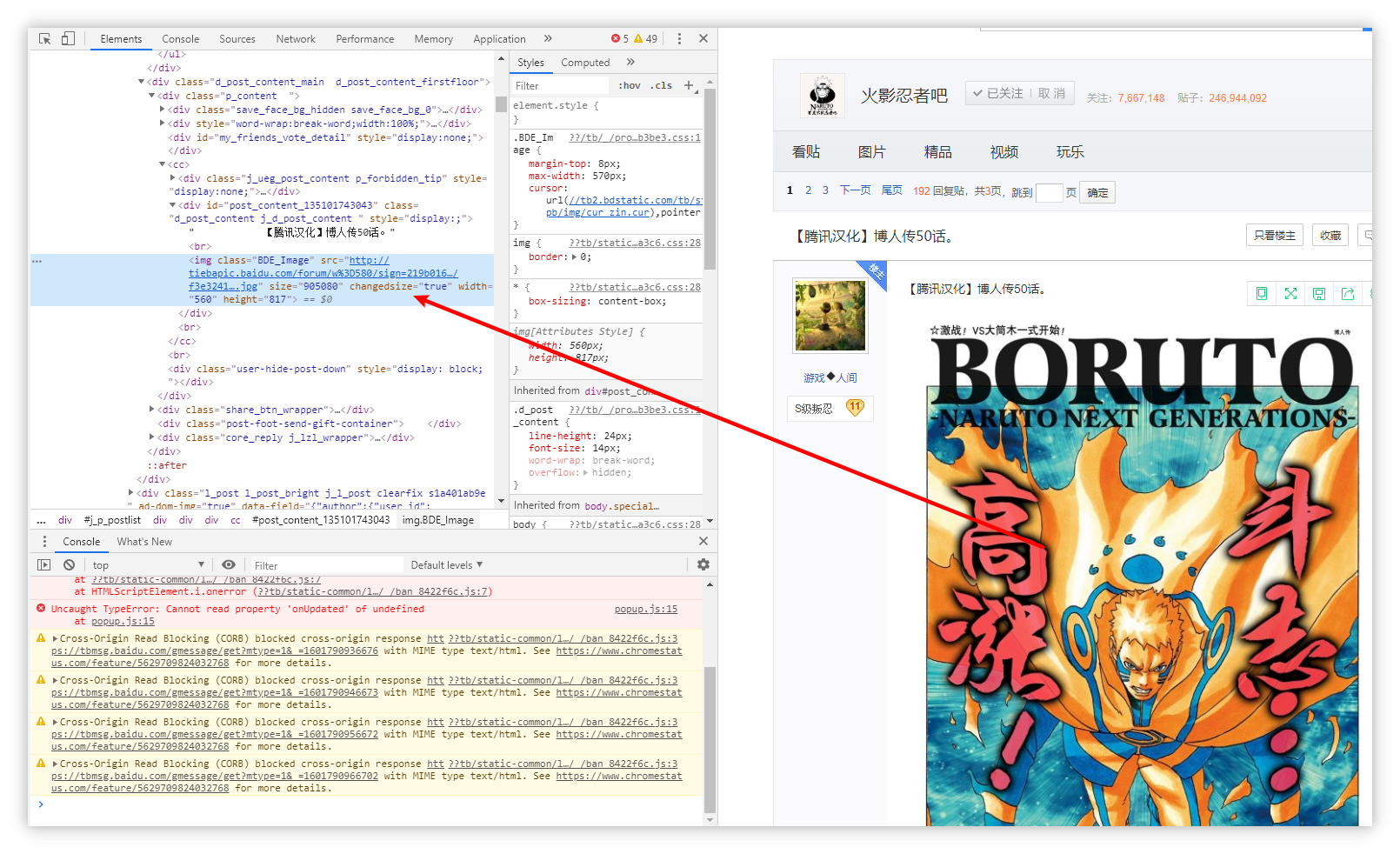
观察文档可知,第一张图片的标签为<img class="BDE_Image" src="http://tiebapic.baidu.com/forum/w%3D580/sign=219b01688545d688a302b2ac94c37dab/f3e3241f95cad1c845e0347c683e6709c83d5144.jpg" size="905080" changedsize="true" width="560" height="817">。
您可以把鼠标悬浮在图片上,然后按下
Ctrl+Shift+C进行快速定位。
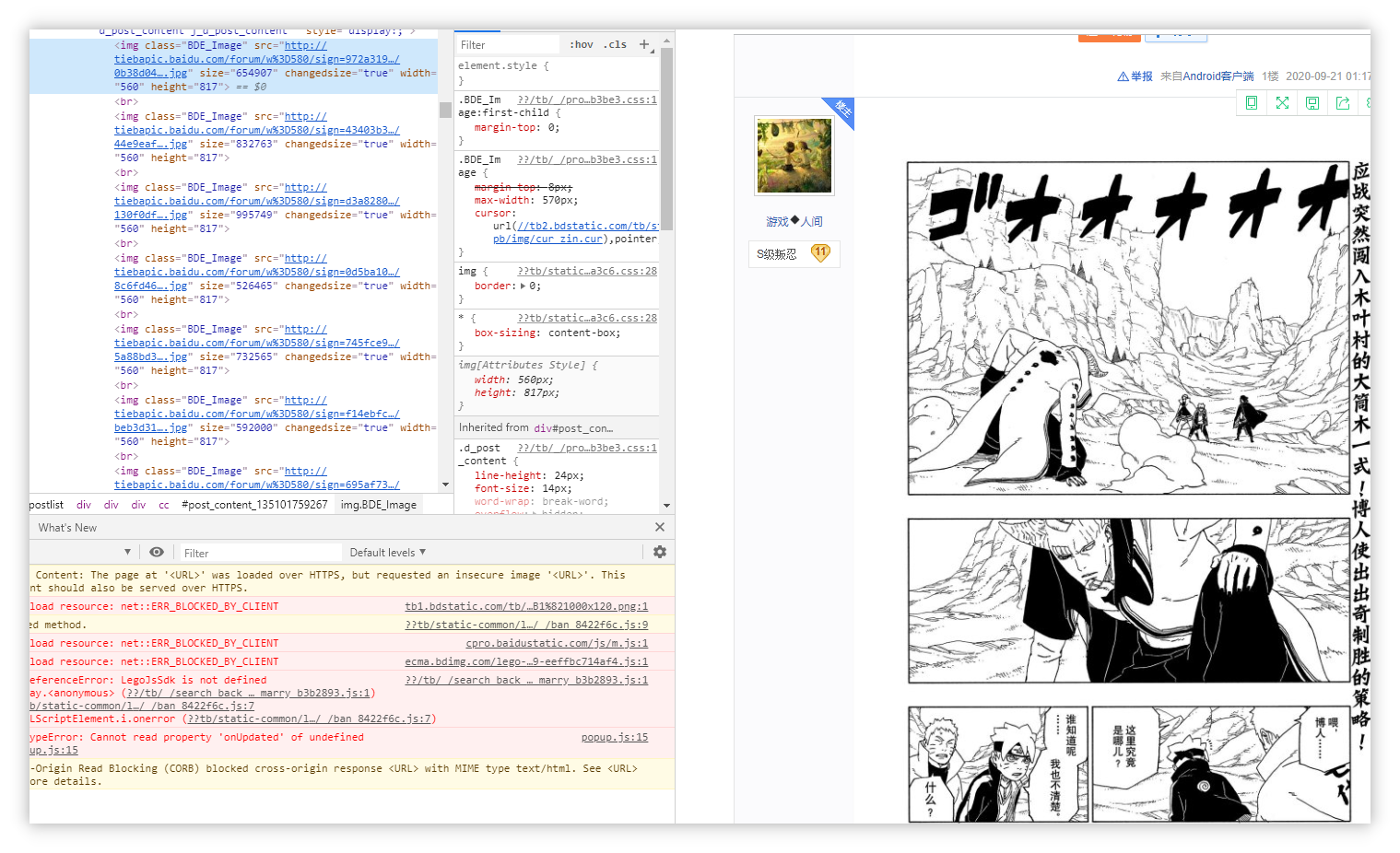
观察后面几张图片,发现共性为img标签,class为BDE_Image,而我们只需要获得src链接即可。

橙色是共性,绿色是需要爬取的内容。
查找标签
由上面的分析易得,我们需要写的代码为:
1 | images = soup.find_all('img',class_='BDE_Image') #这将返回含有每个图片元素的一个列表 |

可以看到我们获得了大量的链接。
接下来只需要下载这些链接的内容即可。
下载图片
此处先直接贴出代码再做解释。
1 | import time |
完整代码
1 | import requests |
爬取豆瓣影评
1 | # 先引用包 |
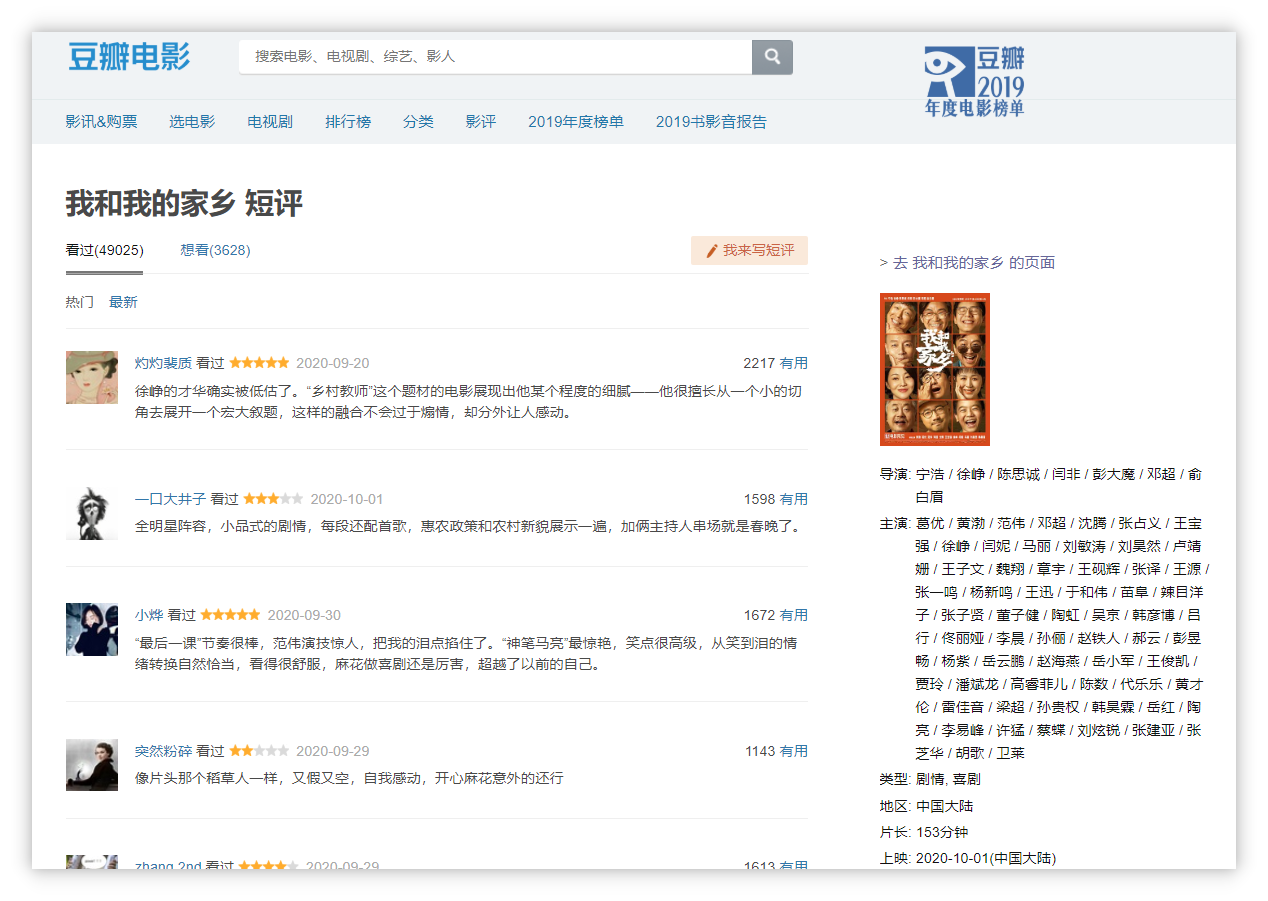
找到要爬取的目标,我选择了这个《我和我的家乡》的影评。链接
获取HTML文档
1 | html = requests.get('https://movie.douban.com/subject/35051512/comments?limit=20&status=P&sort=new_score') |

我们可以看到,直接进行GET请求,返回的状态号为418,并没有成功。
这可能是网站检测出非正常访问,所以我们要伪装成真实人物来访问。
这里就涉及一个User-Agent的概念了,简称UA。这里不解释UA是什么。只说明如何利用。
如何找到UA呢?下面介绍两个方法:
方法一
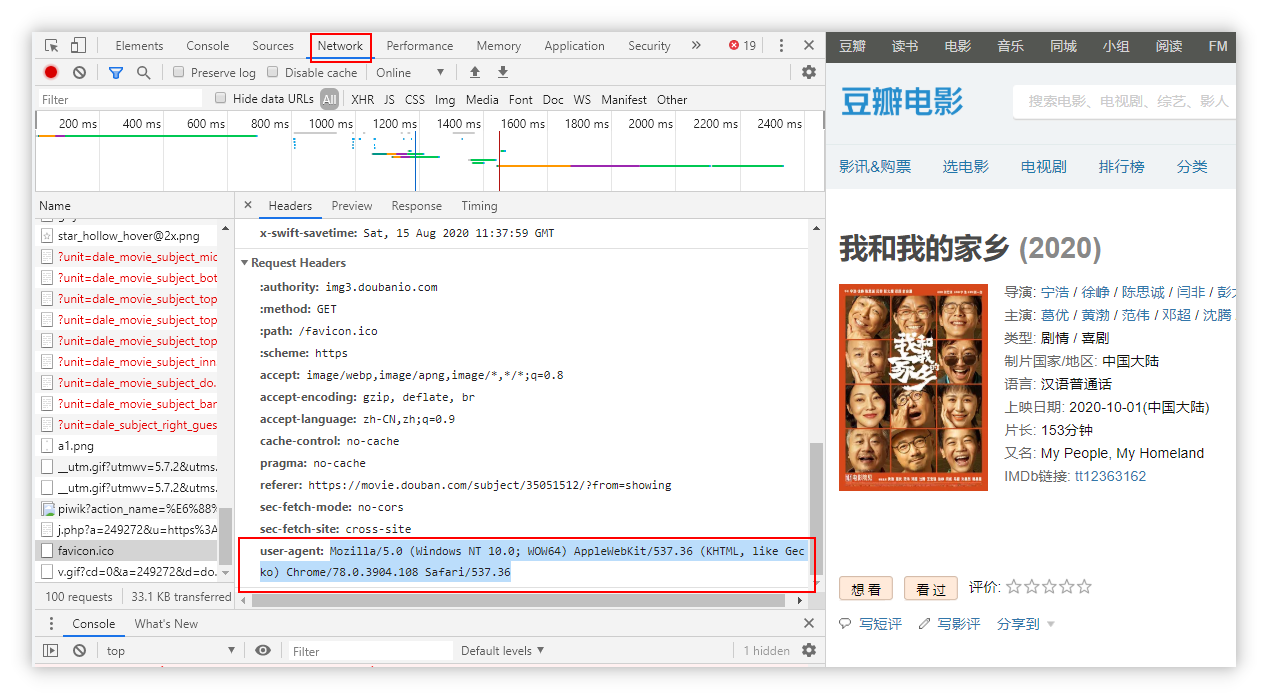
打开F12工具,刷新一下网页。选择Network页签,在左边的选项中随便点一个,在右边的Headers中找到user-agent字段。
即 Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
方法二
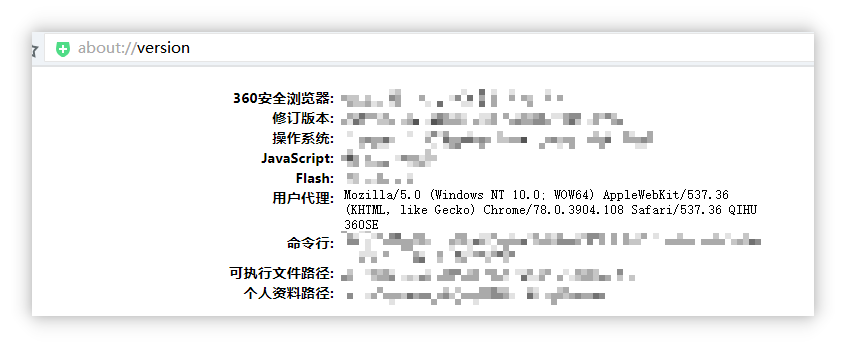
打开浏览器,在地址栏输入about://version并回车。可以方便地找到UA字段。
headers
创建一个字典headers,将刚刚找到的UA,作为字段User-Agent的值写入其中。
1 | headers = { |
接下来将之前的
1 | html = requests.get('https://movie.douban.com/subject/35051512/comments?limit=20&status=P&sort=new_score') |
修改为
1 | html = requests.get('https://movie.douban.com/subject/35051512/comments?limit=20&status=P&sort=new_score',headers=headers) |

这个时候就可以发现能成功请求了。
用BeautifulSoup解析
1 | soup = BeautifulSoup(html.text,'html.parser') |
对网页元素进行选择
我们要爬取的目标是,该电影的影评,最好爬取到尽可能多的内容。
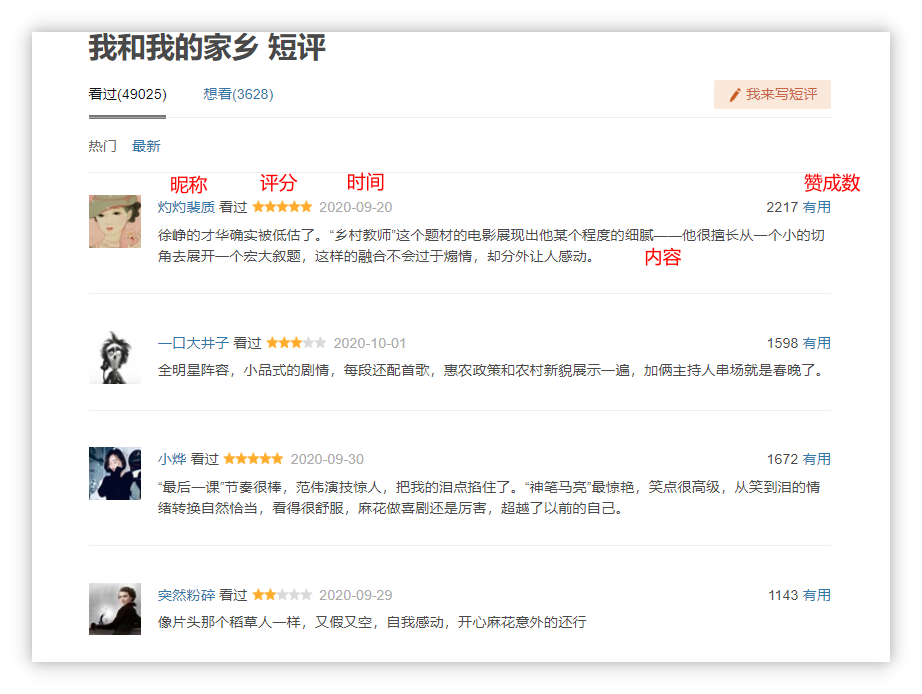
拟定对图上每一个用户的昵称、评分、时间、评论内容、赞成数进行爬取。
打开F12工具进行分析,我们发现每一个用户的评论和其相关信息都在一个div标签,class为comment-item的容器(共同点)中。
注:容器是为方便陈述自己拟定的非正式称谓。
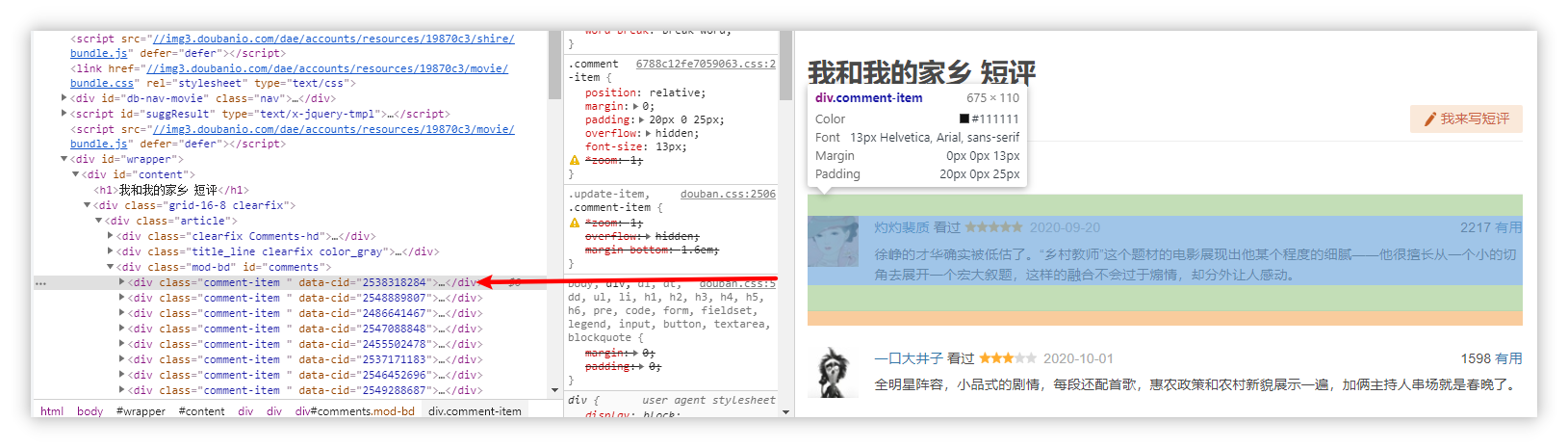
查找标签
思路:我们可以先把页面上所有的容器选出来,再从每个容器中选取自己想要的信息。
1 | boxes = soup.find_all('div',class_='comment-item') |
这样就找到了所有的容器,并以列表的形式返回。
然后我们遍历每个容器,提取自己想要的信息。
1 | for box in boxes: |
这个时候,每个容器中的内容应类似这样(部分内容被隐去):
容器内容
1 | <div class="comment-item " data-cid="2455502478"> |
然后我们再对每个容器进行分析:

赞成数

1 | box.find('span',class_='votes') |
注:我们观察到上面的类写的是 class=“votes vote-count”,这不是一个类的名字,而是两个类的名字,也就是说这个span既属于votes也属于vote-count。
为了提取其中的正文,我们加上.text属性。
1 | box.find('span',class_='votes').text |

用户名
那么如何提取用户名呢?用户名的class为空。和上面提取赞成数类似。
1 | box.find('a',class_='').text |
但是不建议使用这个方法,似乎是会出现BUG。(这个条件太弱了,满足条件可能不止这一个)
所以我们可以采用连续查找的方式,先查找span,class_="comment-info",再在里面查找a标签。

1 | box.find('span',class_='comment-info').find('a').text |
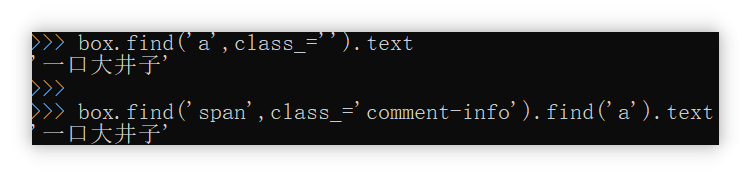
评分
关于评分,我们可以在文档中观察到,没有直接的数字或文本来表示,它是用一个类名来表示的。
所以我们可以想办法获取到这个类名。
1 | box.find('span',class_='rating').get('class') |

在上面那个语句后加一个[0]来获取第一个元素,然后把allstar去掉。
1 | box.find('span',class_='rating').get('class')[0].replace("allstar") |

通过观察可知,30其实是三颗星。所以我们可以简单地换算一下。
1 | int(box.find('span',class_='rating').get('class')[0].replace("allstar",""))//10 |

评论内容
这个也非常简单。
只需要:
1 | box.find('span',class_='short').text |

时间
1 | box.find('span',class_='comment-time').text.strip() |

也可以从属性中取得更详细的时间。
1 | box.find('span',class_='comment-time')['title'] |

完整代码
1 | import requests |
运行效果如下图所示:
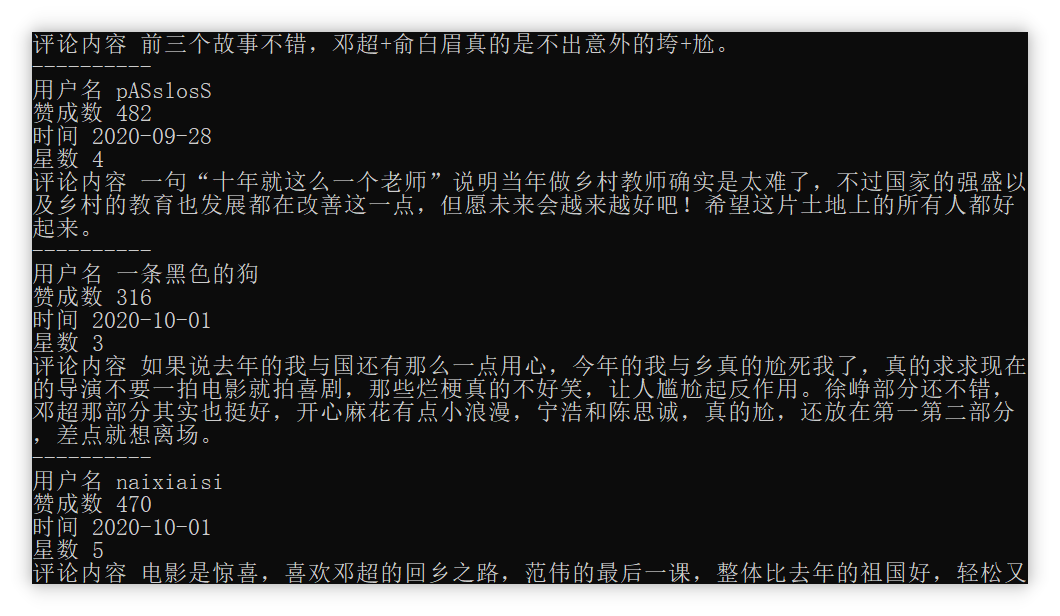
 wechat
wechat alipay
alipay