定义
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n)。
上面这个next()函数,有的地方也把它叫做fail()函数。
背景问题
例如对于下面一个文本串:
ABCDABABCDEAB
模式串为ABCDE
直接可以想到的解法就是,用一个双重循环移位去一位一位地比较。就像下面这个代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| string a="ABCDABABCDEAB",b="ABCDE";
int lena=a.length(),lenb=b.length();
bool flag;
for(int i=0;i<lena;++i){
for(int j=0;j<=lenb;++j){
if(j==lenb) flag=true;
if(a[i+j]!=b[j]) break;
}
if(flag){
cout<<"Succeed at position: "<<i<<endl;
break;
}
}
|
如果匹配起点位置的变化能如下图所示,就可以减少很多次不必要的匹配。

具体实现
理论
next数组其实就是当匹配失败时,起点位置应该从哪里开始。next数组是对模式串进行的预处理
next[i] 表示 P[0] ~ P[i] 这一个子串,使得 前k个字符恰等于后k个字符 的最大的k. 特别地,k不能取i+1(因为这个子串一共才 i+1 个字符,自己肯定与自己相等,就没有意义了)。
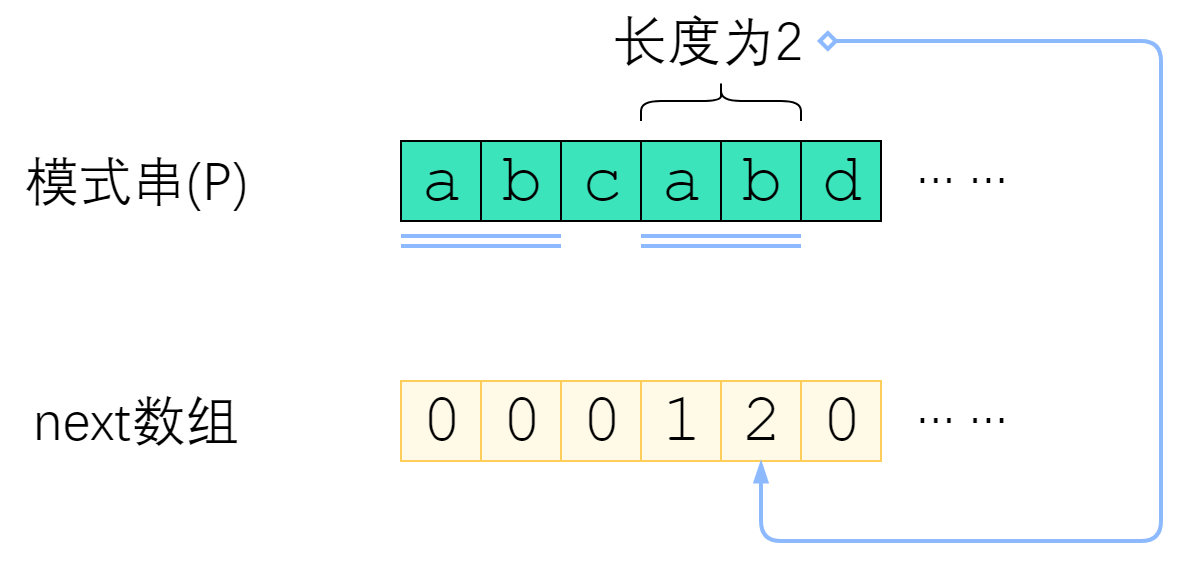
上图给出了一个例子。P=“abcabd"时,next[4]=2,这是因为P[0] ~ P[4] 这个子串是"abcab”,前两个字符与后两个字符相等,因此next[4]取2. 而next[5]=0,是因为"abcabd"找不到前缀与后缀相同,因此只能取0.
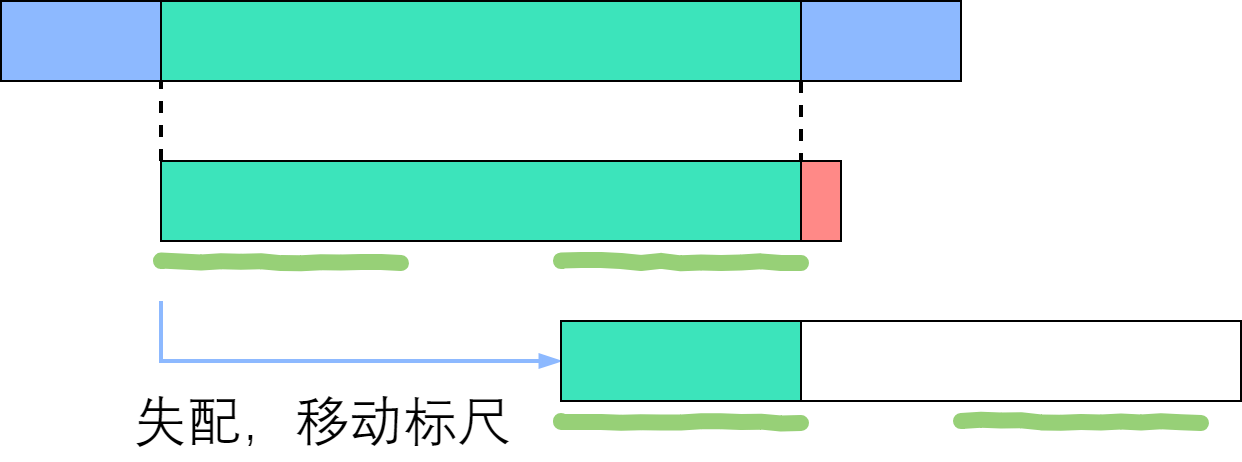
如果把模式串视为一把标尺,在主串上移动,那么 Brute-Force 就是每次失配之后只右移一位;改进算法则是每次失配之后,移很多位,跳过那些不可能匹配成功的位置。但是该如何确定要移多少位呢?
失配之后,标尺移动之后,由于发生失配的位置前绝不可能匹配了,所以起始位置i不用变动,直接变动j就可以了。如果第一位就失配,那么i就要移动一位,所以在next数组里面next[0]标记为-1。
next预处理
普通方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int next[maxn];
next[0]=-1;
012345
for(int i=1;i<lenb;++i){
next[i]=0;
for(int p=i-1;p>=1;--p){
if(b.substr(0,p) == b.substr(i-p+1,i)){
next[i]=p;
break;
}
}
}
|
优化方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
int next[maxn];
next[0]=-1;
int j=0;
int k=-1;
while(j<lenb-1){
if(k==-1||b[j]==b[k]){
++j;
++k;
next[j] = k;
}else{
k = next[k];
}
}
|
比较字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| int i=0;
int j=0;
while(i<lena){
if(a[i]==b[j]){
i++;j++;
}else if(j){
j=nexts[j-1];
}else{
i++;
}
if(j==lenb){
if(t==1) cout<<"Succeed at position: "<<i-j;
break;
}
}
|
方法比较
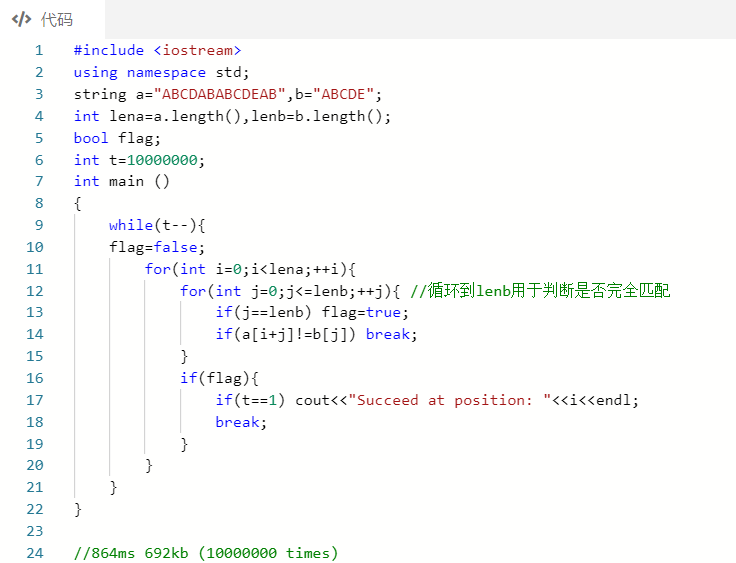

我用的这个字符串例子比较的差距看似还不算特别大,用一些比较长的字符串能更好地体现KMP的性能。
例如string a="ABCDABABCDABABCDABABCDABABCDEAB",b="ABCDE";
详细代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #include <iostream>
using namespace std;
string a="ABCDABABCDEAB",b="ABCDE";
int lena=a.length(),lenb=b.length();
bool flag;
int t=10000000;
int main ()
{
while(t--){
flag=false;
for(int i=0;i<lena;++i){
for(int j=0;j<=lenb;++j){
if(j==lenb) flag=true;
if(a[i+j]!=b[j]) break;
}
if(flag){
if(t==1) cout<<"Succeed at positions: "<<i<<endl;
break;
}
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| #include <iostream>
using namespace std;
string a="ABCDABABCDEAB",b="ABCDE";
int lena=a.length(),lenb=b.length();
bool flag;
int t=10000000;
int nexts[1000];
void getNext(){
nexts[0]=-1;
int j=0;
int k=-1;
while(j<lenb-1){
if(k==-1||b[j]==b[k]){
++j;
++k;
nexts[j] = k;
}else{
k = nexts[k];
}
}
}
int main ()
{
getNext();
while(t--){
int i=0;
int j=0;
while(i<lena){
if(a[i]==b[j]){
i++;j++;
}else if(j){
j=nexts[j-1];
}else{
i++;
}
if(j==lenb){
if(t==1) cout<<"Succeed at position: "<<i-j;
break;
}
}
}
}
|
参考资料
[1] https://www.cnblogs.com/yjiyjige/p/3263858.html
[2] https://www.zhihu.com/question/21923021
[3] 阮行止, https://www.ruanx.net/kmp/

 wechat
wechat alipay
alipay