目标检测 | RCNN 系列目标检测算法详解
思维导图
- RCNN 系列
- R-CNN
- R-CNN 网络结构
- R-CNN 网络效果
- Fast-RCNN
- Fast-RCNN 网络结构
- Fast-RCNN 网络效果
- Faster-RCNN
- Faster-RCNN 网络结构
- Anchor(锚框)
- RPN
- 训练策略
- 监督信息
- Loss
- 回归分支 Loss 计算公式
- 生成 Proposals
- RoI Pooling
- RoI Pooling 不足
- RoI Align
- BBox Head
- 训练策略
- 监督信息
- Loss
- 效果
R-CNN
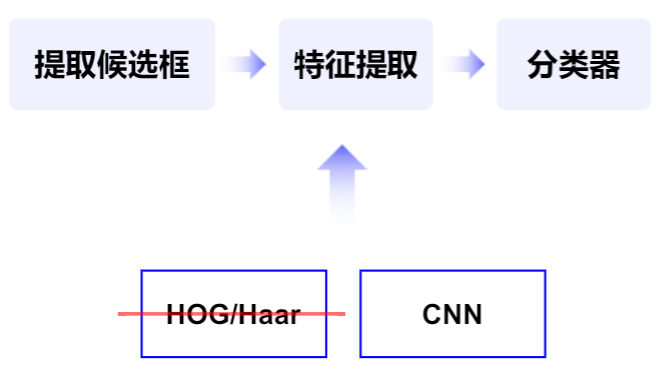
用深度学习分类模型提取特征方法替代传统图像特征提取算法。
R-CNN 核心思想:对每张图片选取多个区域,然后每个区域作为一个样本进入一个卷积神经网络来抽取特征。
R-CNN 网络结构
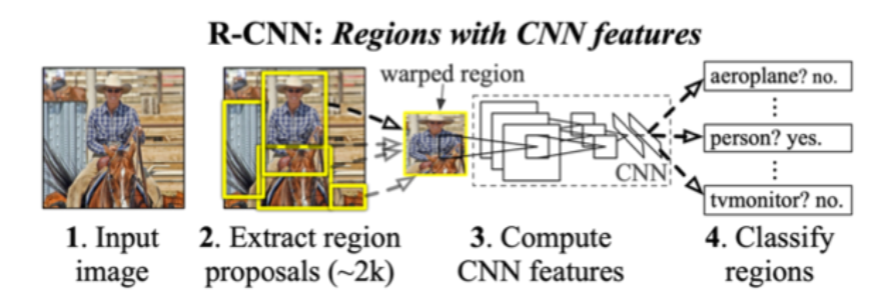
- 每张图会通过Selective Search提取2000个候选区域
- 每个区域被warped到卷积网络要求的输入大小,然后通过卷积网络得到一个输出,作为这个区域的特征
- 使用这些特征来训练多个SVM来识别物体,每个SVM预测一个区域是不是包含某个物体
- 使用这些区域特征来训练线性回归器来对区域位置进行调整
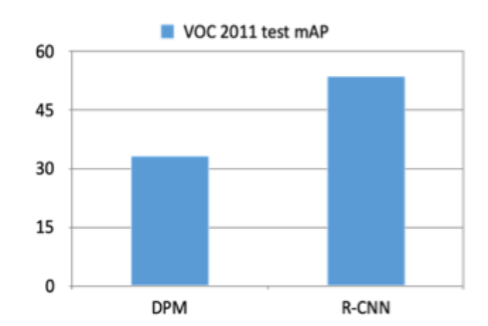
R-CNN 网络效果
R-CNN三大不足︰
- 每个候选区域都需要通过CNN计算特征,计算量大
- Selective Search提取的区域质量不够好
- 特征提取、SVM分类器是分模块独立训练,没有联合起来系统性优化,训练耗时长
Fast-RCNN
核心思想是简化R-CNN计算复杂度。
Fast-RCNN 网络结构
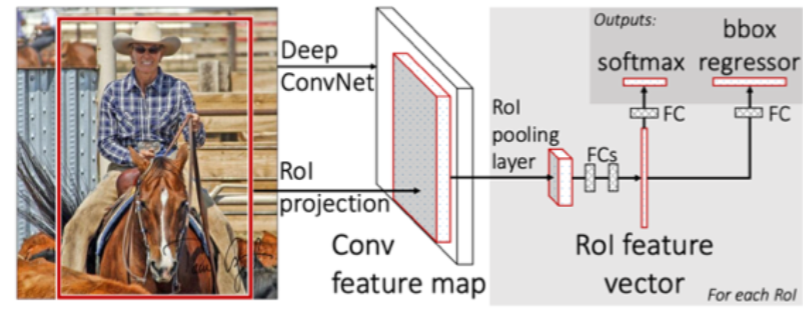
- 把
resize替换为ROI Pooling。将每个区域内均匀分成若干小块,每个小块得到该区域内的最大值 - 把
SVM+Regressor替换为softmax+regressor。
Fast-RCNN 网络效果

相比较先前基于卷积神经网络的检测模型,Fast R-CNN在训练速度和预测速度上都有了很大提升。但是候选区域仍然采用Selective Search的方法,提取候选区域耗时长。
Faster-RCNN
核心思想是用RPN(Region Proposal Network)网络替代Selective Search,用于提取候选区域。
Faster-RCNN 网络结构
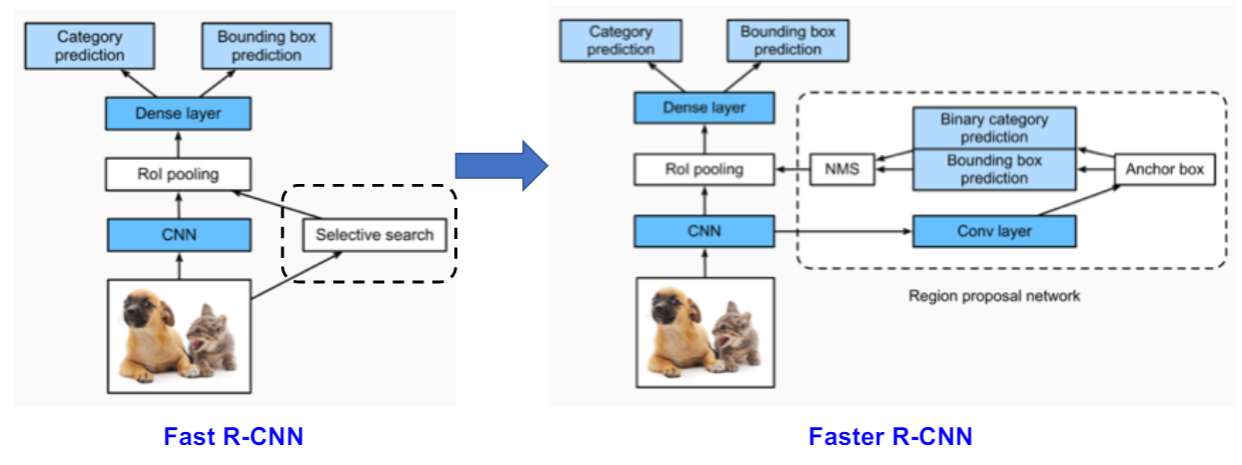
- 第一阶段:产生候选区域
- 使用Anchor替代Selective Search,选取候选区域。
- 选出包含物体的Anchor进入Rol Pooling提取特征。
- 第二阶段:对候选区域进行分类并预测目标物体位置。
Anchor(锚框)
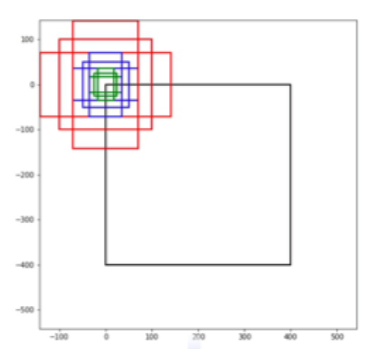
定义:特征图上的每个点作为中心点生成多个大小比例不同的边界框,这些框称为Anchor。
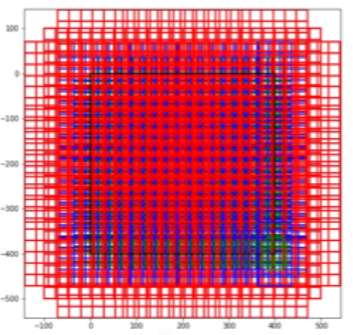
图中红色、蓝色和绿色代表三种Anchor,它们的大小不同。每种Anchor又分成了长宽比为1:2、1:1、2:1的三个Anchor。
特征图每个位置生成9个Anchor。
RPN
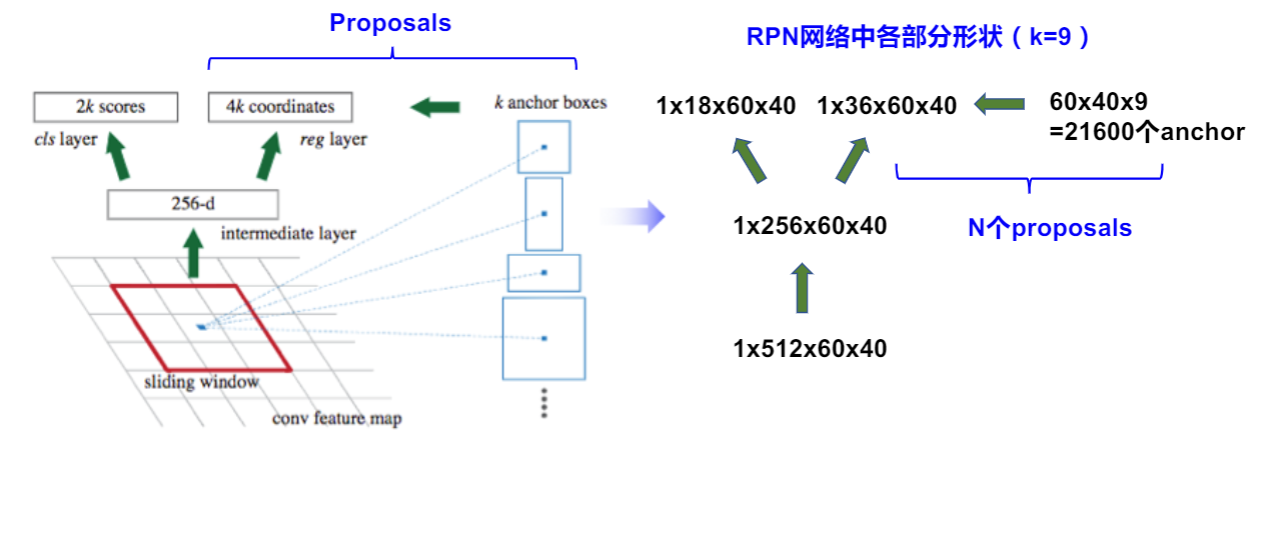
训练策略
- 向RPN网络输入一个监督信息,判断Anchor是
否包含物体。- 正样本:Anchor包含物体
- 负样本:Anchor不包含物体
- 根据Anchor和真实框loU取值,判断正or负样本。
- 正样本:
- 与某一真实框loU最大的Anchor
- 与任意真实框loU>0.7的Anchor
- 负样本:
- 与所有真实框的loU<0.3的Anchor
- 正样本:
- 采样规则:
- 共采样256个样本
- 从正样本中随机采样,采样个数不超过128个
- 从负样本中随机采样,补齐256个样本
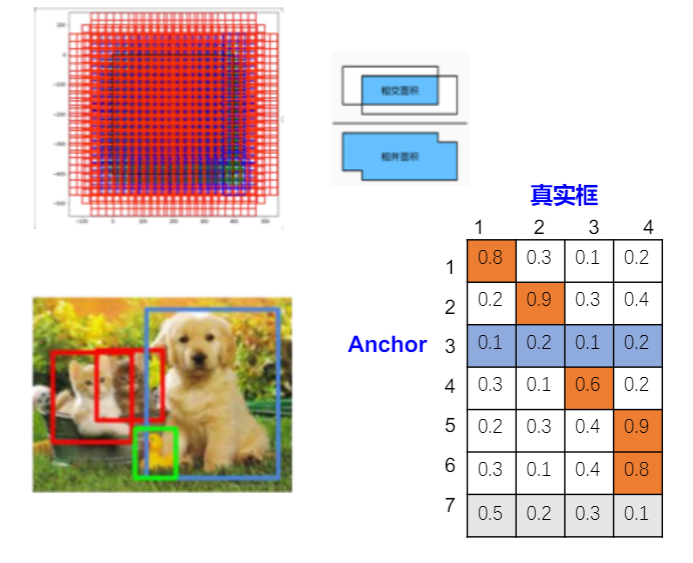
- 正样本:1,2,4,5,6
- 负样本:3
- 既不是正样本也不是负样本:7
监督信息
-
分类分支:候选框是否包含物体
- 正样本-1
- 负样本-0
-
回归分支:Anchor到真实框的偏移量
- ——Anchor
- ——真实框
Loss
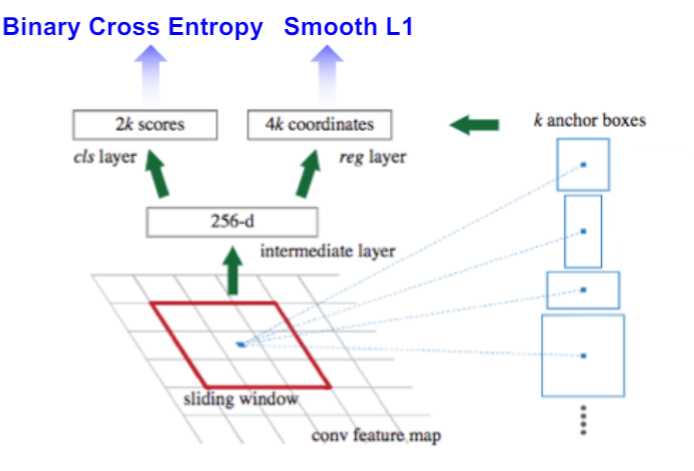
RPN网络的Loss是分类和回归两个Loss相加得到的。
- :分类分支的预测值
- :回归分支的预测值
- :表示分类分支的监督信息,取值为0或1
- 1:表示Anchor为正样本
- 0:表示Anchor为负样本
- :表示回归分支的监督信息
回归分支 Loss 计算公式
其中,
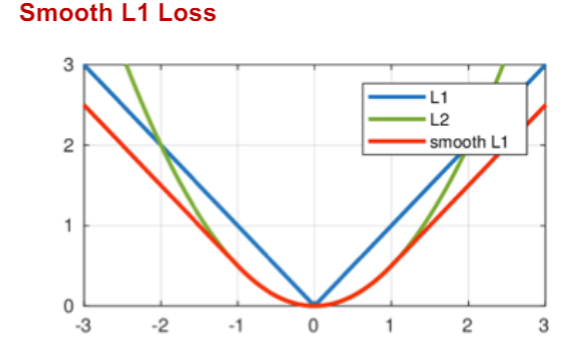
- 当预测框与监督信息差别过大时,梯度值不至于过大;
- 当预测框监督信息差别很小时,梯度值足够小。
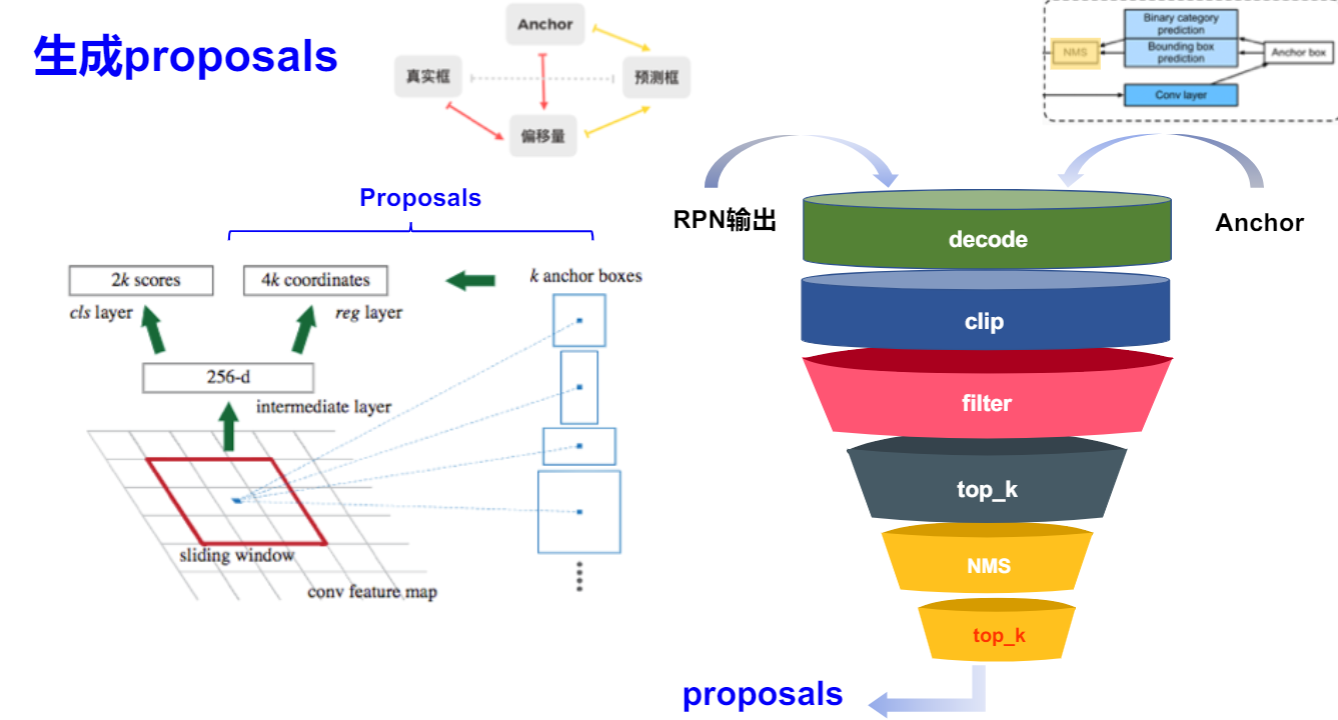
生成 Proposals
RoI Pooling
核心思想∶候选框共享特征图特征,并保持输出大小一致
候选框分为若干子区域,将每个区域对应到输入特征图上,取每个区域内的最大值作为该区域的输出。
RoI Pooling 不足

RoI Pooling 在两次取整近似时,会导致检测信息和提取出的特征不匹配。
- 候选框的位置取整。当RoI位置不是整数时,RoI的位置需要取整。
- 提取特征时取整。划分4个子区域做 max pooling,框的长度需要做近似取整。
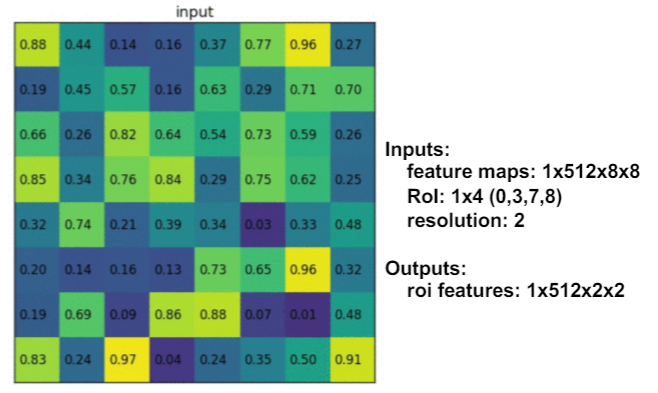
RoI Align
是 RoI Pooling 的改进,核心思想是消除 RoI Pooling 中产生的误差。

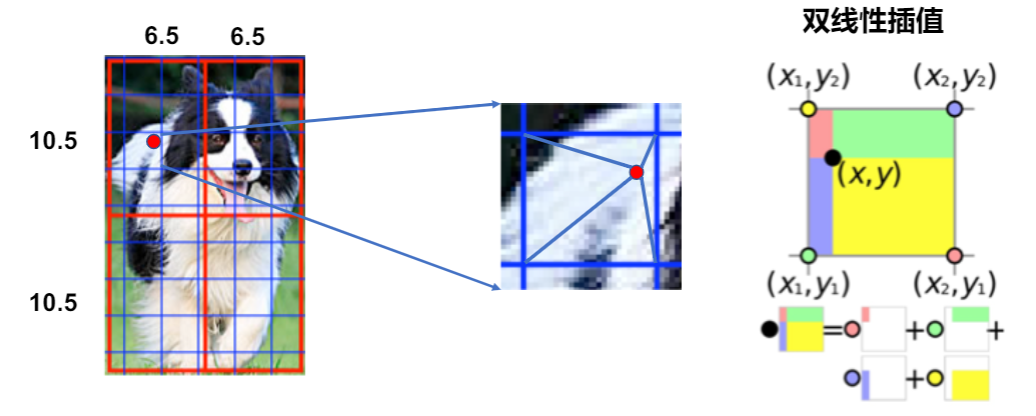
在区域内均匀的取N个点,找到特征图上离每个点最近的四个点;再通过双线性插值的方式,得到点的输出值。最后对N个点取平均得到区域的输出。
BBox Head
训练策略
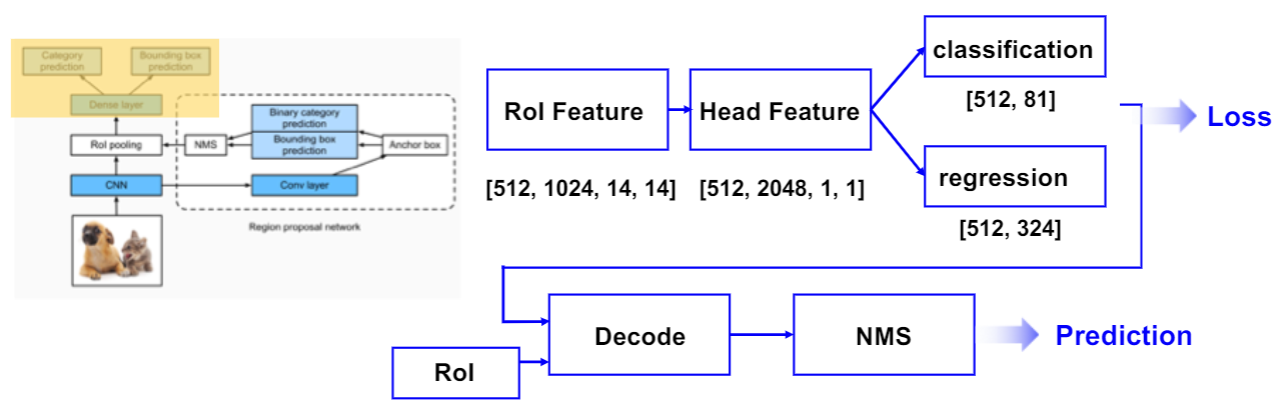
- RoI Feature 经过 Pooling 将特征图从14x14压缩到1x1;然后这个特征经过两个FC作为分类分支和回归分支的预测。最后再去计算 loss 。
- 预测阶段和 RPN 阶段生成 proposals 的过程类似,先将 head 部分的输出和 RPN 输出的RoI解码得到预测框,再进行 NMS 得到最终预测结果。
- 判断Anchor是否包含物体
- 根据IoU判断正or负样本。
- 正样本:IoU>0.7
- 负样本:IoU<0.3
- 采样规则:
- 共采样256个样本
- 从正样本中随机采样,采样个数不超过128个
- 从负样本中随机采样,补齐256个样本
- 判断 RPN 网络产生的 proposals 是否包含物体
- 根据RoI和真实框的IoU,判断正or负样本。
- 正样本:IoU>0.5
- 负样本:IoU<0.5
- 采样规则:
- 共采样512个样本
- 从正样本中随机采样,采样个数不超过128个
- 从负样本中随机采样,补齐512个样本
监督信息
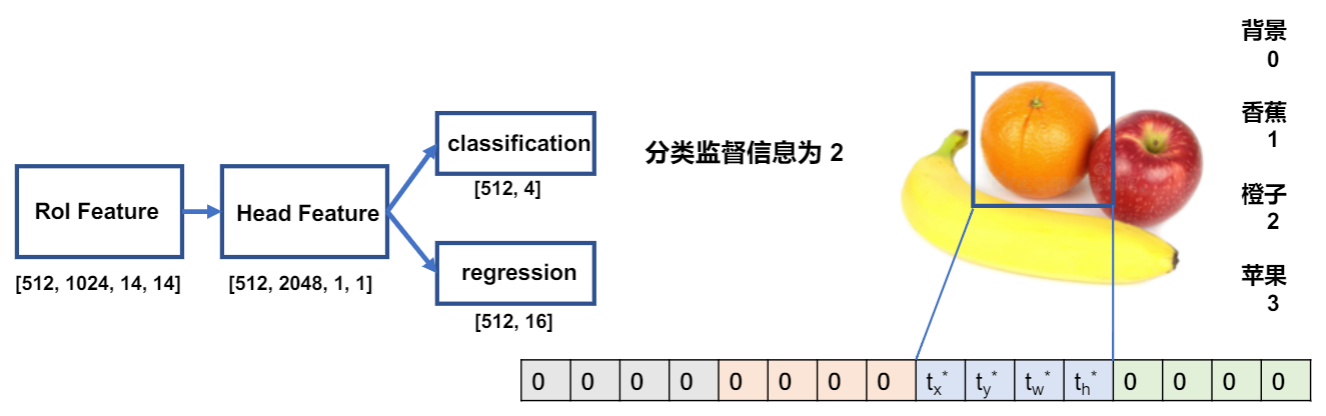
- 分类分支学习每个预测框的类别
- 回归分支学习每个 RoI 到真实框的偏移量
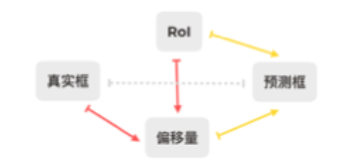
- ——RoI
- ——真实框
Loss
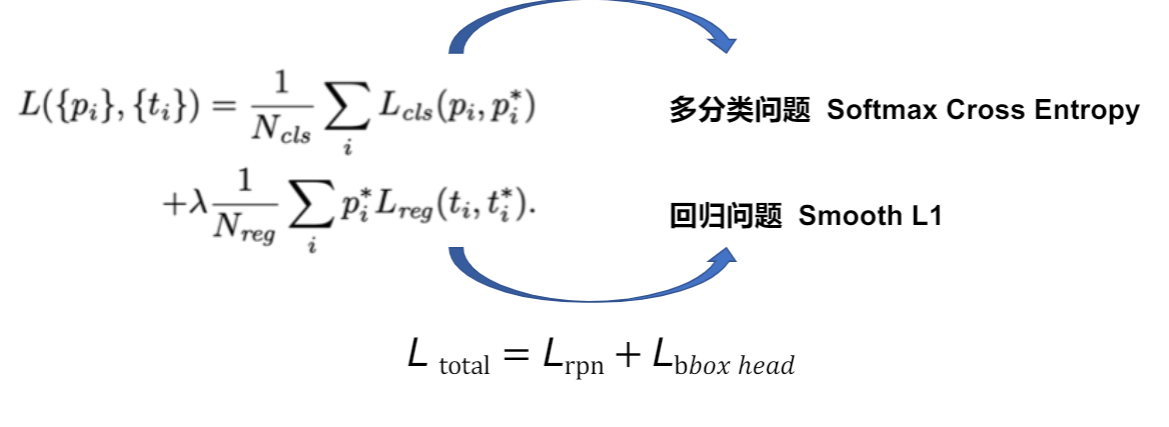
- :分类分支的预测值
- :回归分支的预测值
- :表示分类分支的监督信息,取值为0或1
- 1:表示Anchor为正样本
- 0:表示Anchor为负样本
- :表示回归分支的监督信息
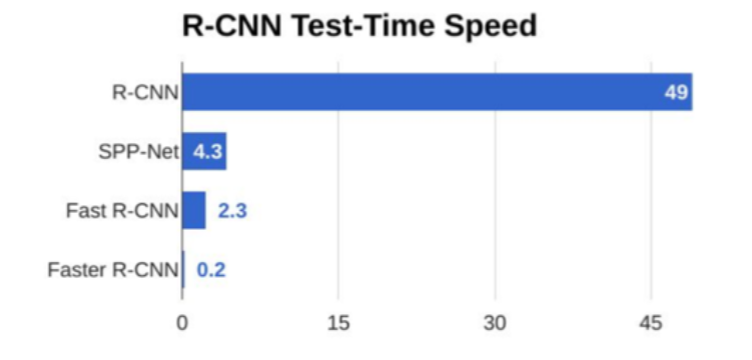
效果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Zorua's Blog!
 wechat
wechat alipay
alipay
相关推荐

评论