目标检测 | RCNN 系列算法优化策略
思维导图
- RCNN 系列算法优化策略
- FPN
- 网络结构
- 目标检测实现方法
- FPN 结构下的 RPN 网络
- FPN 结构下的 RoI Align
- Cascade R-CNN
- IoU 的分析
- 网络结构
- Libra R-CNN
- FPN 特征融合
- 采样策略
- Loss
FPN
FPN 全称为 Feature Pyramid Network。
构造多尺度金字塔,期望模型能够具备检测不同大小尺度物体的能力。
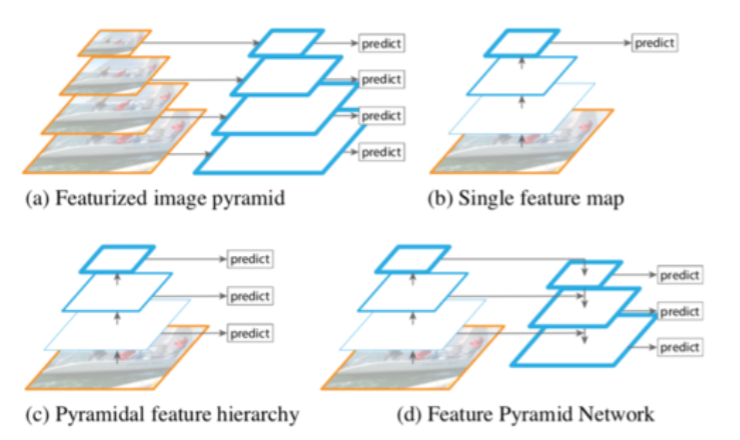
- Featurized image pyramid:将输入图像缩放到不同尺度,使用多个模型进行预测
- Single feature map:仅使用最后一层的特征作为检测模型后续部分的输入
- Pyramidal feature hierarchy:每个层级分别预测
- Feature Pyramid Network(FPN):将不同层的特征进行融合再分级预测
网络结构
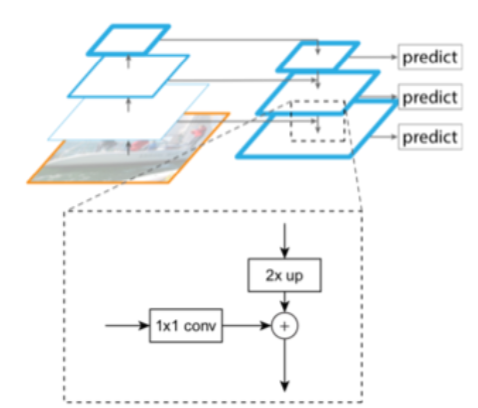
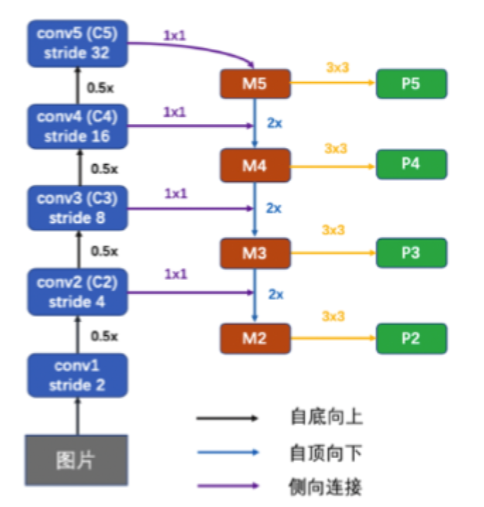
输入为骨干网络每一层的输出;将特征进行上采样,再与上一层特征相加得到 FPN 结构每一层的输出, FPN 结构和骨干网络是相互独立的。
目标检测实现方法
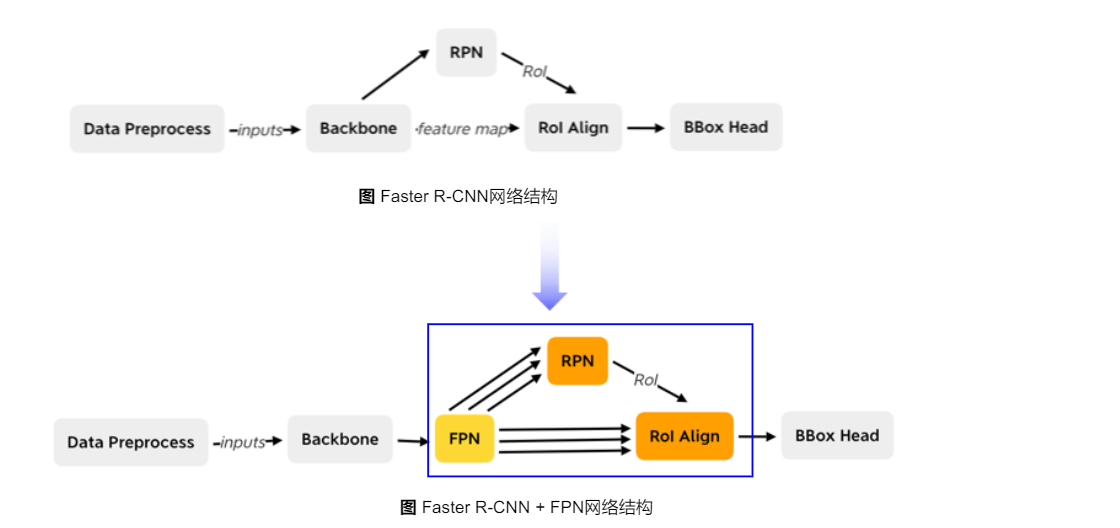
在骨干网络之后增加FPN网络,此时输出的是多个特征图,RPN模块和RoI Align模块会受到影响,第二阶段BBox head不变。
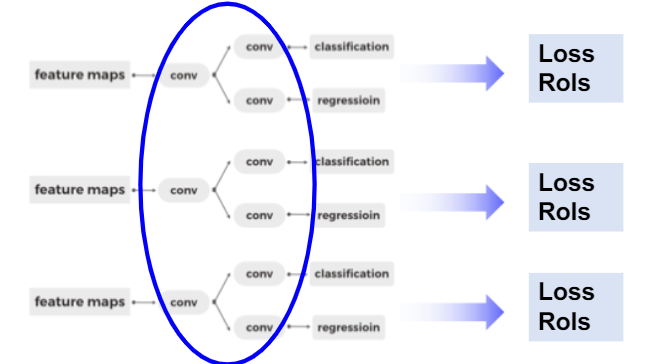
FPN 结构下的 RPN 网络
- Anchor:
- RPN 网络分为多个 head 预测不同尺度上的候选框
- RPN 网络的预测结果和 anchor 解码得到的 RoI 会进行合并
FPN 结构下的 RoI Align
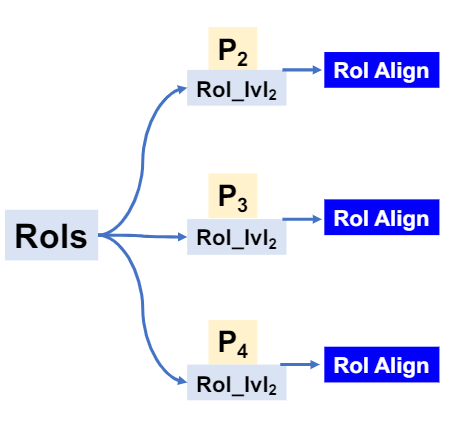
Rol Align:是RoI在特征图上进行特征抽取的过程,并且通过双线性插值的方式去除了坐标点取整的过程。
如何将 RoI 分配到不同层级?
将 FPN 的特征金字塔类比为图像金字塔
根据面积来对候选框进行分配
大个 RoI 放深层,小个 RoI 放浅层。
- :分配的层级
- :基准层
- :RoI的尺寸
- 224:【AI-1000问】为什么深度学习图像分类的输入多是224*224
Cascade R-CNN
Paper: Cascade R-CNN Delving into High Quality Object Detection
核心思想是通过级联几个检测网络达到不断优化预测结果的目的。
IoU 表示两个检测框之间的重叠程度。
Cascade R-CNN 首先对 Faster R-CNN 中的 IoU 的使用进行了分析。
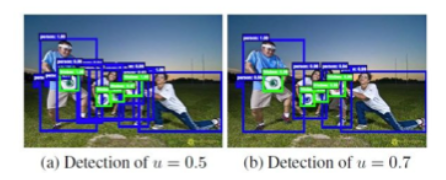
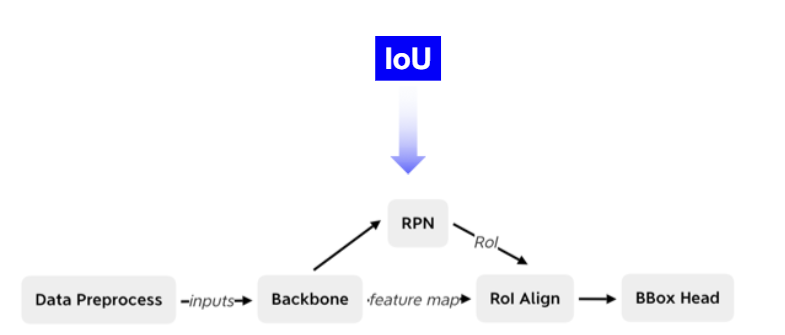
正负样本定义规则︰
- 基于Anchor和真值框IoU匹配值
- IoU>0.7为正样本,IoU<0.3为负样本。
- 基于Proposals和真值框IoU匹配值
- IoU>0.5为正样本,IoU<0.5为负样本
IoU 的分析
如果单纯提高 IoU 阈值,这样后面的detector接收到了更高精度的proposals,自然能产生高精度box。但是这样就会产生两个问题:
- 过拟合问题。提高了IoU阈值,满足这个阈值条件的proposals必然比之前少了,容易导致过拟合。
- 更严重的mismatch问题。
上面的两个问题都会导致性能的下降。[1]
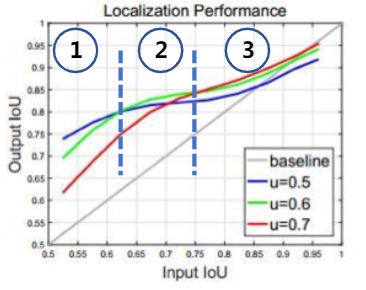
- 横轴:RPN生成的Rol和真值框的IoU;
- 纵轴:经过第二阶段BBox head得到的新的box和真值框的IoU;
- 线条:使用不同IoU阈值筛选出候选框训练出来的模型。
RoI 自身的 IoU 和训练器训练用的阈值较为接近时,训练器的性能最优。
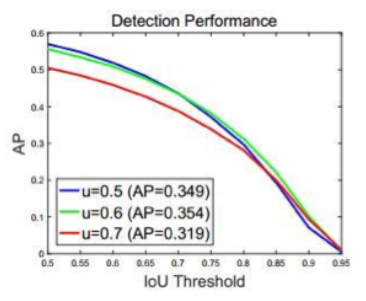
单一阈值训练出的检测器效果非常有限。
引入多个 head 对RoI进行调整。
为了解决以上问题,在多阶段检测架构中提出了级联R-CNN算法,由一系列随着IOU阈值增加而训练的检测器组成,循序渐进的对接近的负例更具选择性。检测器被阶段性的训练,如果检测器的输出是一个好的分布,则用于训练下一个阶段更好的检测器。[2]
网络结构
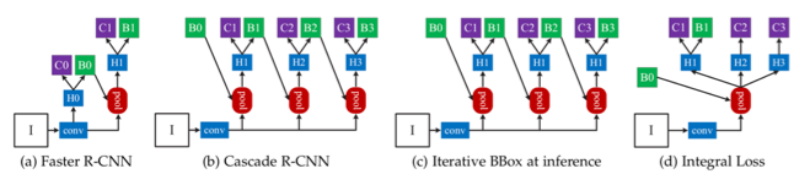
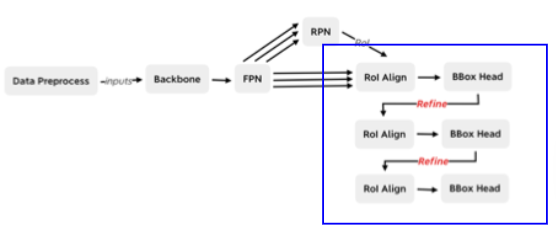
不同改进方式:
- Cascade R-CNN
- 对 box 三次微调,每次 BBox head 的偏移量和 RoI 解码作为下个阶段的 RoI 输入
- lterative BBox
- 三次微调时的权重共享
- lntegral Loss
- 三次微调并联完成,公用同样的 RoI
在这项工作中,作者将假设的质量定义为具有基本事实的IoU,并将检测器的质量定义为用于训练的IoU阈值。基本思想是单个检测器只能针对单个质量水平进行优化,主要区别在于作者考虑了给定IoU阈值的优化,而不是负例比例。
在本文中,作者提出了一种检测器架构 Cascade R-CNN 来解决这些问题,其是 R-CNN 的多阶段延伸,级联更深的检测器对接近的负例有更强的选择性。R-CNN 的级联是按顺序训练的,一个阶段的输出来训练下一阶段,这是由观察到回归器的输出 IoU 几乎总是优于输入 IoU 的动机。用某个 IoU 阈值训练的检测器的输出是良好的分布以训练下一个较高 IoU 阈值的检测器。
Libra R-CNN
检测中的不平衡问题:
- Feature level→提取出的不同level的特征怎么才能真正地充分利用?→FPN特征融合
- Sample level→采样的候选区域是否具有代表性?→采样策略
- Objective level→目前设计的损失函数能不能引导目标检测器更好地收敛? →Loss
FPN 特征融合
- Rescale
- 将不同层级的特征图通过差值或下采样的方法统一到C4层
- Integrate
- 将汇集的特征进行融合
- Refine
- 使用non-local结构对融合特征进一步加强
- Strengthen
- 将优化后的特征与不同层级上的原始特征加和
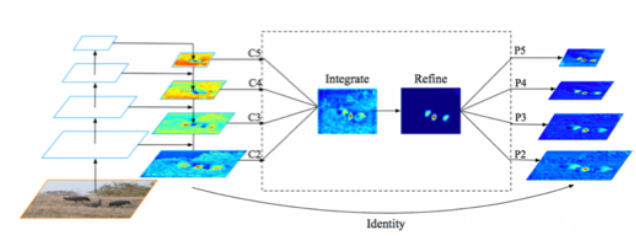
- 将优化后的特征与不同层级上的原始特征加和
采样策略
- 正样本采样:从正样本中随机采样,正样本类别不平衡
- 计算每个类别需要的采样个数
- 每个类别分别进行采样
- 例如∶正样本共20个,包含2类,期望采样4个正样本;那么,每一类随机采样2个正样本
- 负样本采样:从负样本中随机采样,负样本IoU分配不平衡
- 将负样本根据IoU分为两部分
- 大于阈值的样本,根据IoU进行分桶,计算应该落在每个桶中的样本数量,最后得到IoU均匀分布的负样本
- 低于阈值的样本随机采样
Loss
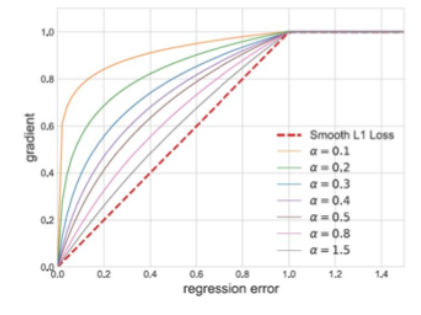
把 Smooth L1 Loss换成了Balanced L1 Loss。
- Loss 较大的样本认为是困难样本
- Loss 较小的样本是容易样本
- Smooth L1 中困难样本对应的梯度相对于容易样本的梯度更大,导致不同样本学习能力的不平衡
- Balance L1 中,困难样本和容易样本界限处的梯度更加平滑
Cascade R-CNN 详细解读, 过若干, https://zhuanlan.zhihu.com/p/42553957 ↩︎
 wechat
wechat alipay
alipay