目标检测 | YOLO 系列算法发展历程
思维导图
- YOLO 系列算法发展历程
- 学习资料
- YOLO 原理简述
- YOLO 开山之作 —— YOLOv1
- YOLOv2
- YOLOv3
学习资料
YOLO 原理简述
以YOLOv1为例,简述YOLO的核心思想。
- 将图像划分成SxS个网络
- 物体bbox中心落在哪个网格上,就由该网格对应锚框负责检测该物体。
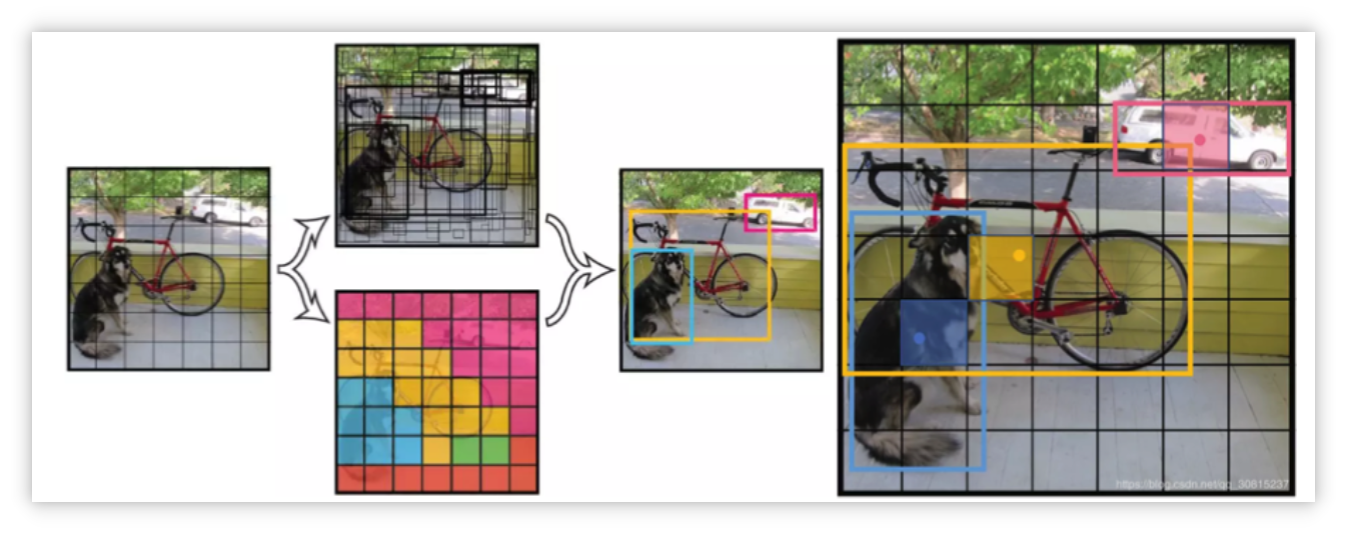
- 输出特征图的宽度、高度(H,W)为SxS,即SxS个网格。
- 输出特征图的通道上有等信息。
- 在官方提出的YOLOv1中,特征图的每个位置预测两个bounding box(bbox),而每个bbox包含五个输出参数:置信度,矩形框参数,共10个参数,再加上20个类别,一共就是30了。置信度C的作用是判断此处是否有目标的中心点。每个网格都会给出个预测参数,因此,网络最终输出的预测参数总量就是
- 之所以是20个类别,是因为那时候的数据集只有PASCAL VOC,共20个类别,COCO还没提出来。
因此,YOLOv1就是在每个网格上去做预测,理想情况下,包含了物体中心点的网格会有很高的置信度输出,而不包含中心点的网格的置信度输出应该十分接近0。
总的来说,YOLOv1一共有三部分输出,分别是objectness、class以及bbox:
- objectness就是上面所说的框的置信度,用于表征该网格是否有物体;
- class就是类别预测;
- 而bbox就是边界框(bounding box)。
YOLO 开山之作 —— YOLOv1
- 单阶段目标检测模型
- 名字来源是 You Only Look Once
- 将目标检测当做一个单一的回归任务,仅使用一个卷积神经网络端到端地实现检测物体的目的。
YOLOv2
- 优化方法
- 骨干网络:224x224 -> 448x448,DarkNet19
- 全卷积网络结构:Conv + Batch Norm
- KMeans 聚类 Anchor
- 多尺度训练
- 待改进点
- 小目标上召回率不高
- 靠近的群体目标检测效果不好
- 检测精度还有优化空间
YOLOv3
- 优化方法
- 骨干网络:DarkNet53
- 多尺度预测
- 跨尺度特征融合
- COCO数据集聚类9种不同尺度Anchor,每个尺度3个
- 分类使用Sigmoid激活,支持目标多分类
- 待改进点
- 召回率相对较低
- 靠近的群体目标检测效果较差
- 定位精度仍需优化
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Zorua's Blog!
 wechat
wechat alipay
alipay
相关推荐

评论